Just tech hype?
These days serverless computing is all the rage – most cloud providers cater for it one way or another. But what use is it? Is it here to stay or is it going to be another one day wonder?
The internet is full of such ideas which have fallen by the wayside after much enthusiasm. Reading about it is great, but understanding serverless computing as an organisation takes far more than that.
What types of tasks and/or payloads are suitable? What models of computation? Maintenance? Costs? These questions are numerous, but until we have used serverless for something real we did not feel we would understand if it is worth it. We decided to try out serverless computing in a few low-risk projects as part of Invotra Labs.
One of these projects was an in-house web metrics API proof of concept (POC), which is most likely going to be developed in an integrated Invotra metrics API.
Experiment with analytics
Currently, at Invotra we rely on Matomo for all our analytics needs. It provides all the expected metrics, adds some niceties like page overlay, and looks like a great fit. And it is, unless you have big clients, who generate large data.
This is when things can go south quickly. Archiving takes ages – hours to days – even if you throw some serious iron at it. The reason for this is that a regular SQL database like mariadb is not suited for the types of queries web analytics demand. A columnar, or document database may perform better. So we decided to experiment, and develop a proof of concept to evaluate the feasibility of developing an in-house analytics or metrics service, that can be used to meet most of the reporting needs inside the product, and allow clients to use the data in third-party business intelligence tools.
The proof of concept provides a restful API, with endpoints delivering answers to questions such as the number of page hits, downloads or visits, with a number of predefined filters like date ranges, segments, site sections, etc…
What follows is a discussion of serverless computing using examples based on the metrics experiment.
What is serverless computing?
In serverless computing, applications are hosted by a third-party service, eliminating the need for server maintenance by the developer. Architecturally, applications become a set of functions that can be invoked and scaled individually. Obviously, code maintenance still remains, but the scope of responsibility is significantly narrowed. This allows for more concentration on core business, shifting traditional server software and hardware maintenance to the third party.
Serverless computing presupposes stateless computing, in the sense that no state is preserved locally between function/endpoint invocations. There is no native application state. Any long-term state lives in some sort of external database, or other storage. This requirement is not new. The success of PHP as a web programming language for the masses is partially due to eliminating application state from the interpreter, and each request standing on their own.
On the surface, the decomposition of an application into functions makes the application look more like a library. That is not a new idea either, just look at any API. The serverless infrastructure takes care of the routing of requests and function invocation. That is what allows service providers to scale functions individually – the unique offering of this model.
Serverless computing on the AWS platform
At Invotra, we use AWS, and Amazon’s serverless offerings are Lambda and Lambda@Edge. The latter executes code at the edge network, as close as possible to the client, in Cloudfront. Although interesting, and undoubtedly useful, we are not considering using it at the moment.
Our Invotra Labs experiments, as well as the metrics POC, are in AWS Lambda.
The high-level client-facing flow looks like the diagram below:

- A client makes a HTTP(s) request to an endpoint, let’s say / resource GET /resource?param1=x
- the request is translated by the AWS API gateway to a lambda function invocation. This can take into account authentication, parameters, and other details
- The lambda function does its business and returns its result to the API gateway
- This, in turn, translates the method response into proper HTTP(s) for the client and forwards it onward
There is a 15-minute time limit for any lambda invocation. It will be automatically killed by Amazon beyond that.
In each request, there are at least three parties involved. The client could a web browser, a BI program and some home spun software (or other software).
The API gateway is responsible for the processing and routing of client requests, similar to express in the NodeJS world. The flow for each endpoint routed by the API Gateway for the app is visible in the AWS console. The screenshot below is from the metrics POC. The HTTP flow and some of the configuration options are visible. Going through the full configuration is beyond the scope of this post, however, I may detail it in some other post down the line.
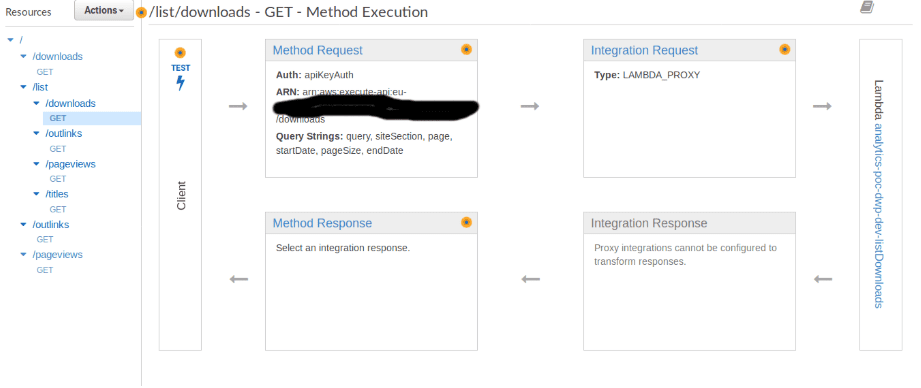 API Gateway console screenshot
API Gateway console screenshot
The lambda console allows the creation, configuration and monitoring of lambda functions. The screenshot below shows the lambda console for one of the endpoint functions.
 AWS lambda console screenshot
AWS lambda console screenshot
Full applications can and (probably) have been developed using the browser-based tools, but it is painful and hardly maintainable. To avoid this, we are using the serverless javascript framework. It allows us to treat both the code and the amazon configuration the same way – API gateway, lambda and more.
How do we use serverless, architecture of the metrics POC, code and warts? Read all about it in the next instalment.